ITIL - Gestion des Tickets et Incidents
Maîtrisez les processus ITIL de gestion des incidents et des problèmes : ticketing, escalade, SLA et bonnes pratiques TSSR.
Introduction
ITIL (Information Technology Infrastructure Library) est un référentiel de bonnes pratiques pour la gestion des services IT. Ce cours se concentre sur les processus de gestion des tickets, des incidents et des problèmes, essentiels pour un Technicien Supérieur Systèmes et Réseaux (TSSR).
Processus ITIL de Ticketing
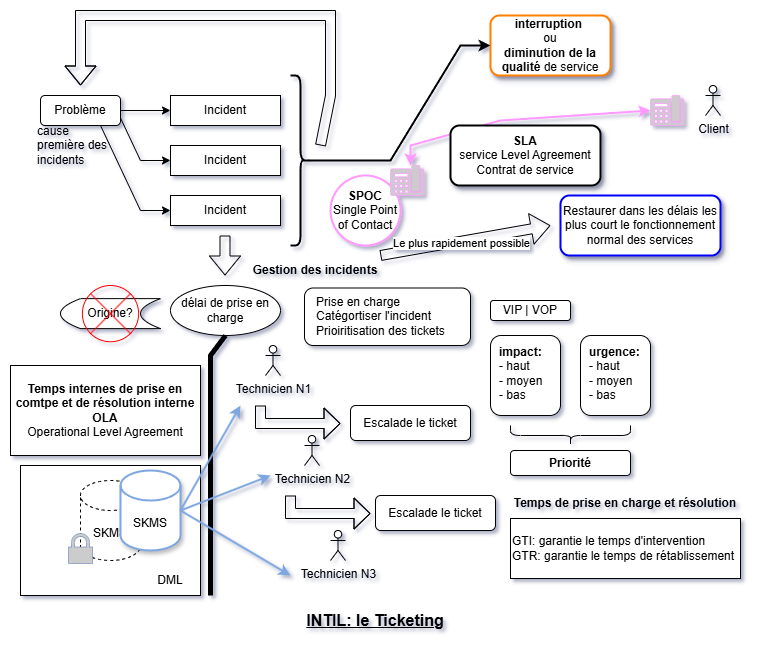
Diagramme synthétisant le processus ITIL de gestion des tickets
1. ITIL : Vue d'ensemble
ITIL est un ensemble de recommandations qui définit comment organiser et gérer les services informatiques d'une entreprise. Ce n'est pas une norme obligatoire, mais un cadre de travail (framework) reconnu mondialement.
Pour un TSSR, ITIL est crucial car il structure le travail quotidien : gestion des tickets, résolution d'incidents, documentation, communication avec les utilisateurs, respect des délais contractuels (SLA).
Le cœur de l'activité TSSR repose sur deux processus majeurs : la gestion des incidents (restaurer le service rapidement) et la gestion des problèmes (trouver la cause racine pour éviter les récurrences).
2. Incident vs Problème : Différence fondamentale
Incident (selon ITIL) : Une interruption non planifiée d'un service, une dégradation de la qualité de service, ou une panne d'élément de configuration qui n'impacte pas encore le service (ex: disque en RAID qui tombe).
Problème (selon ITIL) : La cause sous-jacente d'un ou plusieurs incidents. C'est l'origine profonde qui génère les symptômes (incidents).
ATTENTION : Un incident ne se transforme JAMAIS en problème. Un incident est causé par un problème. On décide de traiter le problème si l'incident est répétitif ou grave.
Exemple concret
Si plusieurs utilisateurs ne peuvent plus accéder à leurs fichiers (incidents), la cause peut être une panne du serveur de fichiers suite à une surtension électrique (problème). Les incidents sont les symptômes, le problème est la cause racine.
3. Gestion des Incidents : Objectif et Chronologie
Objectif unique : Restaurer le fonctionnement normal du service aussi rapidement que possible, dans le respect du SLA. On ne cherche PAS à trouver la cause racine, on restaure !
Si un PC est infecté par un virus, on redéploie l'image master. Si un serveur tombe, on bascule sur le serveur de secours. L'important est le rétablissement rapide, pas l'analyse approfondie.
La gestion des incidents suit toujours des procédures strictes, même pour les incidents majeurs. La qualité en IT, c'est la régularité : deux fois le même problème = deux fois le même temps de résolution.
4. Chronologie d'un Incident
1. Détection : L'incident arrive par appel téléphonique, email, système de surveillance, ou interface web.
2. Identification : Est-ce vraiment un incident ? Ou une demande de service ? Ou une réclamation ?
3. Enregistrement du ticket : Création systématique d'un ticket dans l'outil ITSM (ex: GLPI, ServiceNow). Traçabilité obligatoire.
4. Catégorisation : Type d'incident (matériel, logiciel, réseau, etc.)
5. Priorisation : Calcul de la priorité (Impact × Urgence = Priorité)
6. Incident majeur ? Si oui, appliquer la procédure spécifique (mobilisation de tous les experts dès le début)
7. Diagnostic initial : Est-ce de mon ressort ? Puis-je le résoudre ?
8. Résolution ou Escalade : Si je peux résoudre, je résous. Sinon, j'escalade.
5. Les Types d'Escalade
Escalade fonctionnelle : Le problème technique est trop complexe pour mon niveau de compétence. Je transfère le ticket au niveau supérieur (N1 → N2 → N3) avec TOUTES les informations collectées pour éviter au N2 de refaire le travail.
Escalade hiérarchique : Le problème est grave (pas forcément complexe). Exemple : le contrôleur de domaine est tombé. Même si je sais comment le réparer, c'est si critique que je dois alerter immédiatement le responsable (propriétaire du service) pour qu'il gère la communication et la gestion de crise.
Différence clé
Escalade fonctionnelle = "c'est trop dur pour moi". Escalade hiérarchique = "c'est trop grave, mon manager doit être au courant".
6. Incident Majeur : Procédure Spécifique
Un incident majeur a un fort impact métier (coûte cher) et une priorité élevée. Exemples : serveurs de production inaccessibles, réseau complet down, perte de données critiques.
Ce qui change : On applique une procédure différente mais on reste dans une procédure ! Erreur fréquente = paniquer et tout faire n'importe comment.
Dès le début, on mobilise TOUS les experts (ingénieur réseau, ingénieur système, etc.) pour résoudre rapidement. Pas d'escalade progressive, tout le monde est sur le pont immédiatement.
CRUCIAL : Continuer à enregistrer les actions dans le ticket ET désigner une personne pour communiquer avec les clients. Ne jamais oublier la communication même en crise.
Si l'incident majeur touche le réseau, ne PAS communiquer par email ! Prévoir d'autres canaux : téléphone, messagerie externe, affichage, etc.
7. Modèles d'Incident
Pour les incidents récurrents, on crée des modèles d'incident : procédures étape par étape pour traiter l'incident de manière standardisée.
Exemple : "Problème de connexion Internet" → Étape 1 : Vérifier l'icône réseau, Étape 2 : Ping de la gateway, Étape 3 : Vérifier le câble, etc.
Avantages : Cheminement toujours identique (qualité), durée de résolution connue, utilisable par des débutants (niveau 1 / Service Desk).
8. Gestion des Problèmes : Objectifs
La gestion des problèmes a des objectifs radicalement différents de la gestion des incidents :
1. Prévenir l'apparition des problèmes (approche proactive : agir AVANT que le problème survienne)
2. Éliminer les incidents récurrents en traitant la cause racine
3. Minimiser l'impact des incidents qui ne peuvent être totalement évités
Contrairement aux incidents (rapidité), ici on prend le temps nécessaire pour trouver la solution définitive.
9. Chronologie d'un Problème
1. Détection et enregistrement : Le problème peut provenir de la gestion des incidents, de la gestion des événements, ou être identifié en interne.
2. Priorisation : Comme pour les incidents (impact × urgence)
3. Investigation et diagnostic : Recherche de la cause première. On travaille souvent sur une maquette (environnement virtualisé) pour ne pas bloquer la production.
4. Solution de contournement ? Si possible, on met en place une workaround provisoire (ex: revenir à la version précédente d'un logiciel). ATTENTION : le ticket reste OUVERT !
5. Création d'une erreur connue (Known Error) : Documentation dans la base de connaissances AVANT la résolution, pour que le Service Desk puisse proposer la solution de contournement.
6. Request For Change (RFC) : Si la résolution nécessite un changement, on demande l'autorisation à la gestion des changements.
7. Résolution : 4 phases → Observation, Hypothèses, Conception des tests, Réalisation des tests. Tout doit être écrit !
8. Clôture et mise à jour de la base de connaissances
9. Revue des problèmes majeurs : Analyse rétrospective pour améliorer le processus (points positifs, points à améliorer)
10. Proactif vs Réactif
Réactif : On résout le problème APRÈS qu'il soit survenu. Exemple : mise en place de monitoring pour détecter plus vite la prochaine fois.
Proactif : On empêche le problème de survenir. Exemple : mise en place d'un onduleur pour éviter les pannes dues aux coupures électriques, mise en place de RAID pour éviter la perte de données.
Une bonne gestion des problèmes est si efficace qu'on a l'impression qu'elle ne sert à rien... car il n'y a plus de problèmes !
11. SLA, OLA, GTI, GTR
SLA (Service Level Agreement) : Contrat de service entre le fournisseur IT et le client. Définit les engagements de niveau de service (disponibilité, temps de réponse, etc.).
OLA (Operational Level Agreement) : Accord interne entre équipes IT. Définit les temps de prise en charge et de résolution entre services (ex: entre N1 et N2).
GTI (Garantie de Temps d'Intervention) : Délai maximum pour commencer à travailler sur l'incident après sa création.
GTR (Garantie de Temps de Rétablissement) : Délai maximum pour restaurer le service normal.
Ces délais sont contractuels et doivent être respectés. La priorisation des tickets dépend de ces SLA.
12. Service Desk et SPOC
Service Desk : Point d'entrée unique pour toutes les demandes IT (incidents, demandes de service, questions). C'est l'équipe de niveau 1 (N1).
SPOC (Single Point Of Contact) : Principe ITIL qui impose un point de contact unique pour les utilisateurs. Ils n'appellent PAS directement le technicien N2 ou N3, tout passe par le Service Desk.
4 types de Service Desk : Local (sur site), Centralisé (un seul centre pour toute l'entreprise), Follow-the-Sun (plusieurs centres dans le monde pour couvrir 24/7 sans heures sup), Spécialisé (centres experts par domaine technique).
13. Priorisation : Impact × Urgence = Priorité
La priorité d'un ticket se calcule en croisant l'impact métier et l'urgence.
Impact : Nombre d'utilisateurs affectés, criticité du service. Haut/Moyen/Bas.
Urgence : Rapidité nécessaire pour résoudre. Haute/Moyenne/Basse.
Exemple : Impact HAUT + Urgence HAUTE = Priorité CRITIQUE (VIP). Impact BAS + Urgence BASSE = Priorité BASSE.
La priorité détermine l'ordre de traitement des tickets et les SLA applicables. Un ticket P1 (critique) sera traité avant un P4 (faible), même si le P4 est arrivé avant.
14. Communication avec l'Utilisateur
Visibilité : Le client doit TOUJOURS savoir où en est son ticket. Ne jamais laisser un utilisateur sans nouvelles pendant 3 heures !
Informer régulièrement : "Votre ticket est pris en compte", "Le technicien intervient", "Une pièce est commandée", "Le problème est résolu".
Ce n'est PAS naturel de communiquer pendant qu'on travaille, mais c'est ESSENTIEL. C'est souvent ce qui fait la différence entre un bon et un mauvais service IT.
Pour les incidents majeurs : désigner UNE personne responsable de la communication pendant que les autres résolvent.
15. Base de Connaissances (KEDB)
KEDB (Known Error Database) : Base de données des erreurs connues et de leurs solutions. Enrichie au fur et à mesure par la gestion des problèmes.
Le Service Desk consulte systématiquement la KEDB avant d'escalader : peut-être que la solution est déjà documentée !
Bonne pratique : documenter les solutions dans la KEDB dès qu'un problème est résolu, surtout s'il risque de se reproduire.
16. Séparation Incidents / Problèmes
ITIL recommande fortement de séparer physiquement la gestion des incidents et la gestion des problèmes :
- Équipes différentes si possible, ou au minimum lieux de travail différents
- Raison : les objectifs sont opposés. Incidents = vitesse, problèmes = analyse approfondie. Mélanger les deux crée de la confusion.
Si vous êtes seul, séparez mentalement : "Là je gère un incident, je dois aller vite" vs "Là j'analyse un problème, je prends mon temps".
Toujours créer un ticket, que ce soit pour un incident ou un problème. Traçabilité = qualité.
17. Bonnes Pratiques TSSR
1. Toujours créer un ticket, même pour une intervention de 2 minutes. Traçabilité obligatoire.
2. Respecter les procédures, même en urgence. Une procédure différente, mais toujours une procédure.
3. Communiquer régulièrement avec l'utilisateur. Ne jamais le laisser sans nouvelles.
4. Documenter vos actions dans le ticket au fur et à mesure, pas à la fin. Mémoire courte !
5. Escalade intelligente : transférer les informations collectées, ne pas faire refaire le travail au N2.
6. Prioriser selon SLA, pas selon qui crie le plus fort. Le directeur n'est pas toujours prioritaire si son impact métier est faible.
7. Apprendre de chaque incident majeur : revue rétrospective pour améliorer continuellement.
8. Enrichir la KEDB avec chaque nouvelle résolution intéressante.